

Immersio
Language Learning Platform
During my school years, I had the opportunity to participate in the Industry Sponsored Student Projects (ISSP), where students and sponsors collaborate to develop software solutions. One of the projects I worked on was with Immersio, a language-learning platform. Their goal was to implement a system that could collect, store, retrieve, and analyze user activity within their platform. I saw this as a valuable opportunity to strengthen my backend development skills. The project itself was a challenging yet rewarding experience since we had flexibility to choose the technologies. This meant we had to put significant effort into evaluating and selecting the right tech stack.
Project Kickoff: Understanding Client Needs
Every project starts with a client meeting, and ours was no exception. During our first discussion with Immersio, we explored their existing system and their technical preferences. Fortunately, they wanted this new system to be built separately from their existing architecture, which gave us more flexibility in technology choices. However, there was one key requirement:
- The database had to be NoSQL because user activities would involve complex data structures with multiple event categories.
After our initial meeting, we designed the system architecture and began evaluating NoSQL database options. We considered three primary choices:
- MongoDB Atlas
- AWS DynamoDB
- Redis
- Flexible Data Schema – Easily accommodates different types of user activity data.
- Supports Complex Filtering – Allows efficient querying and data retrieval.
Project Development: Building the system
We proposed three high-level features to the client:
- Trace Data Models: Carefully designed NoSQL data models to track various event categories.
- Backend Microservice: A backend system consume, analyze, and integrate user activity data into database.
- QA & Stress Testing System: A framework for real-time stress testing to ensure system stability
- Data Modeling Team
- Backend Microservice Team
- Pipeline & QA Team
I was honored to be part of the Data Modeling Team, where our first task was to design a schema that supported both user-specific and platform-wide activity tracking. For example, the client wanted to track individual user activity while also being able to analyze aggregated activity across all users for a specific lesson, such as "Korean 101 - Quiz 1." To achieve this, we designed a hierarchical data structure in MongoDB that allowed for efficient querying and analysis. Once we had a solid data schema, we moved on to developing the backend and connecting it to MongoDB Atlas.
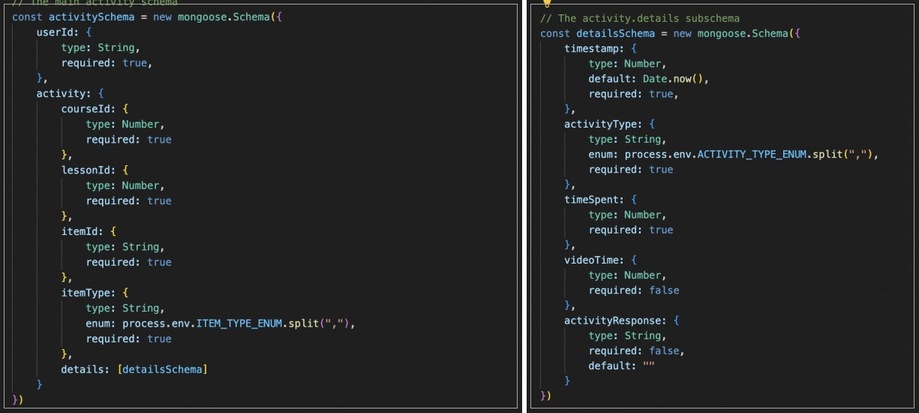
Backend API Development
Our Node.js backend included the following API endpoints:
- Get / - Use this to view all of the stored activities in the database.
- Put / - Use this to store a new activity in the database. If the activity already exists, it will add a new subschema to the details list.
- Get /getByItem/{itemId} - Use an itemId as a parameter to retrieve all activities from all users for a specific item.
- Get /user/{userId} - Retrieve all activities for a specific user by using their userId as the parameter.
- Get /{id} - Retrieve a single activity by using the unique document id of that activity.
- Put /{id} - Update a specific activity by using the unique document id of that activity.
- Delete /{id} - Delete a specific activity by using the unique document id of that activity.
- Put /update/{id} - Use this to update the activity response of a specific details subschema.
- Post / - Store generated data into Database.
Final Phase: Data Simulator & Mock Front-end
As the project neared completion, we realized that a mock front-end would be helpful for demonstrating our work. However, at that time, I was focused on developing the Data Simulator, one of my favorite features in this project.
What is the Data Simulator?
The Data Simulator generates realistic, human-like user activity data for analysis. This helps Immersio test and optimize their learning platform.
How We Built It
- We used Apache JMeter for load testing to see if the backend could handle concurrent user requests.
- The client wanted requests to be sent at an interval of 10 to 30 seconds, then gradually reduce the interval to test server performance.
- We implemented the Faker library in Node.js to generate realistic random data.
- A Node.js backend service continuously generated and stored simulated user activity in MongoDB Atlas.
- We developed a mock front-end to visually display the real-time data generation process.
This simulated data allowed the client to analyze system performance, optimize queries, and improve the platform's user experience and you can see our final architecture for the new system below.
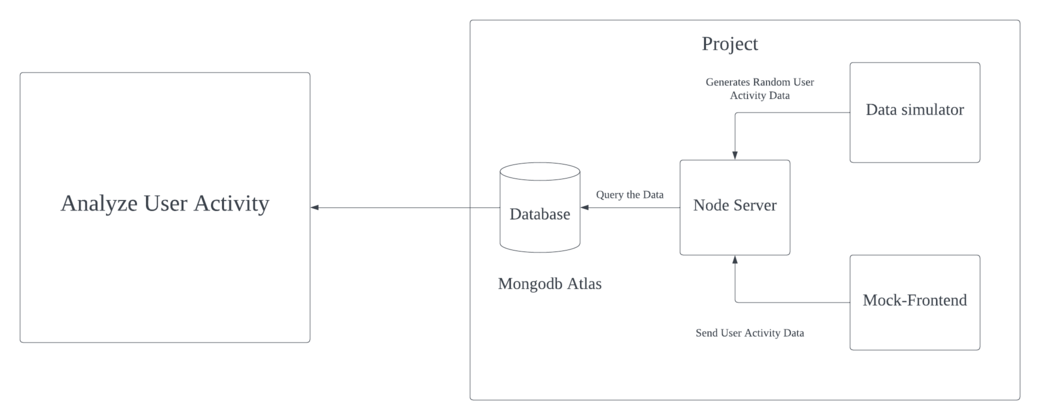
Lesson Learned
By the end of the project, we had successfully built a scalable, data-driven system that:
- Collected and stored user activity data
- Used MongoDB Atlas for efficient NoSQL data storage
- Provided powerful filtering and retrieval options
- Simulated real-time user activity for testing & analysis
The project itself gave me hands-on experience in:
- Backend architecture & microservices
- NoSQL database design (MongoDB Atlas)
- Load testing & data simulation
- Collaborating in a agile environment